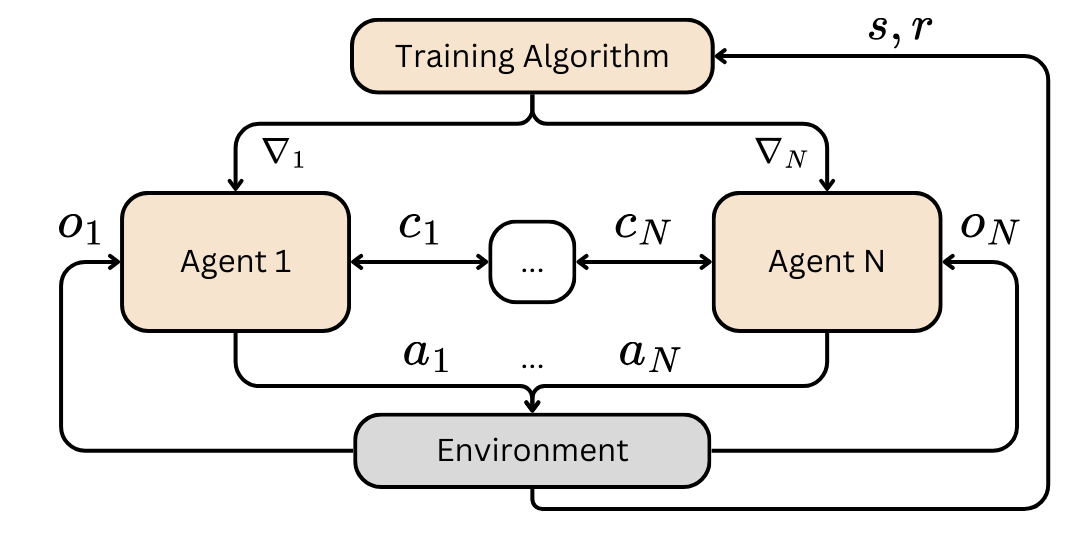
MADRL systems.

Multi-Agent Deep Reinforcement Learning (MADRL) was proven efficient in solving complex problems in robotics or games, yet most of the trained models are hard to interpret. While learning intrinsically interpretable models remains a prominent approach, its scalability and flexibility are limited in handling complex tasks or multi-agent dynamics. This paper advocates for direct interpretability, generating post hoc explanations directly from trained models, as a versatile and scalable alternative, offering insights into agents' behaviour, emergent phenomena, and biases without altering models' architectures. We explore modern methods, including relevance backpropagation, knowledge edition, model steering, activation patching, sparse autoencoders and circuit discovery, to highlight their applicability to single-agent, multi-agent, and training process challenges. By addressing MADRL interpretability, we propose directions aiming to advance active topics such as team identification, swarm coordination and sample efficiency.
@misc{poupart2025perspectives,
title={Perspectives for Direct Interpretability in Multi-Agent Deep Reinforcement Learning},
author={Yoann Poupart and Aurélie Beynier and Nicolas Maudet},
year={2025},
eprint={2502.00726},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2502.00726},
}