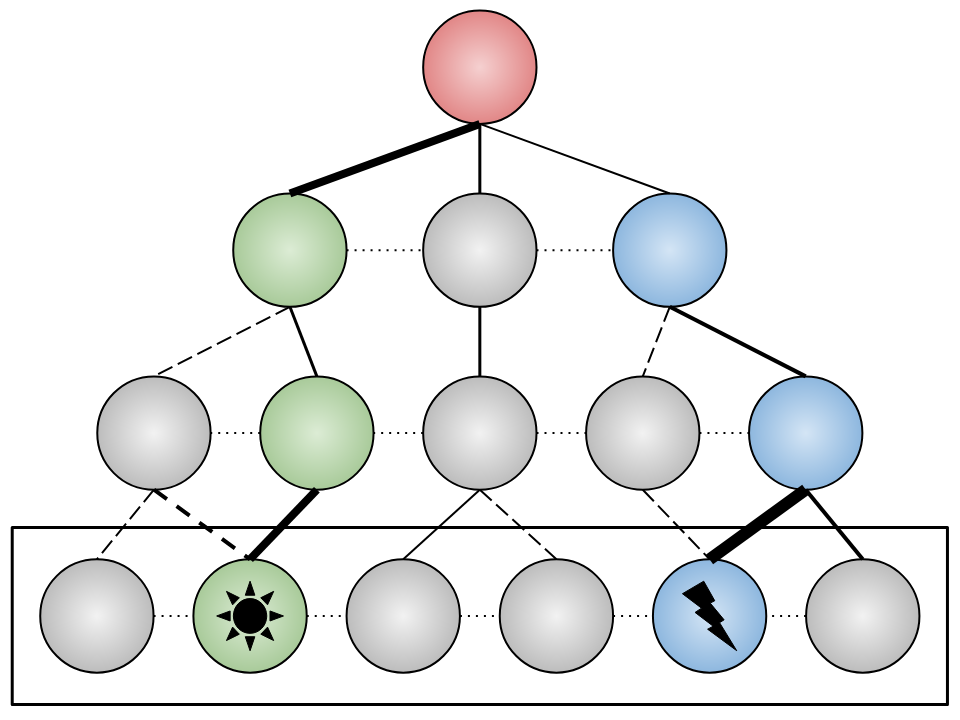
Dynamical concepts illustration.
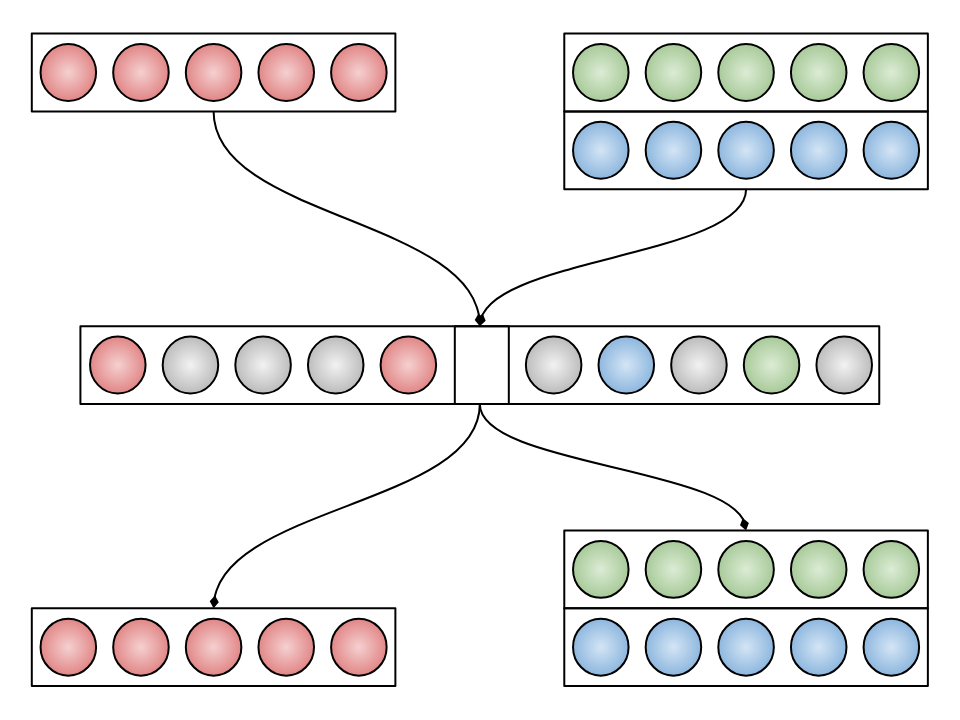
Contrastive Sparse Autoencoders (CSAE) schematic view.
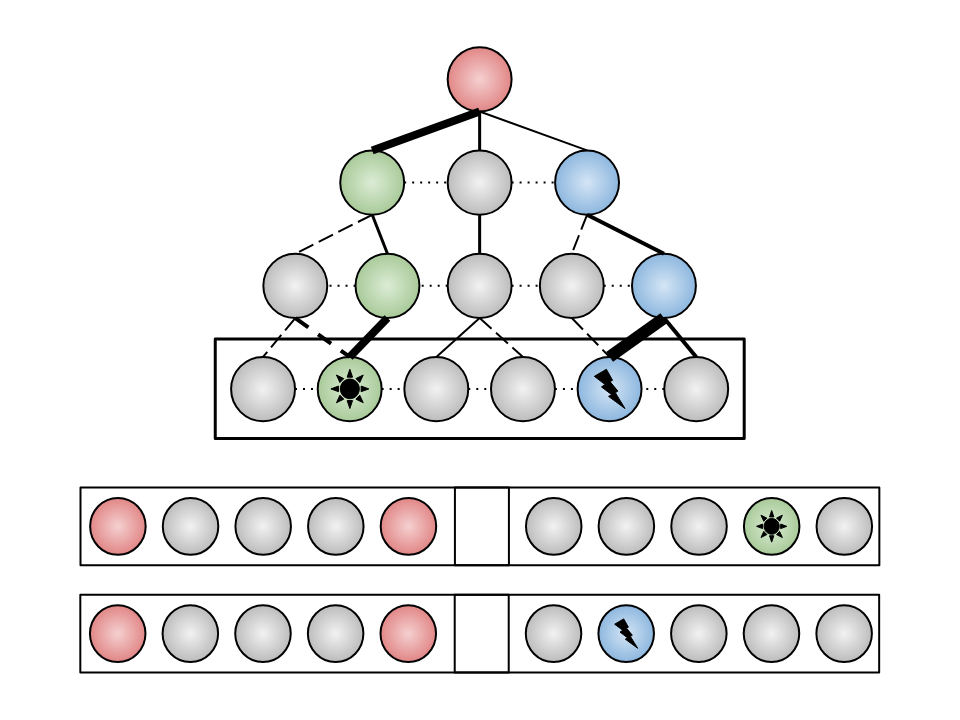
Dynamical concepts extraction.
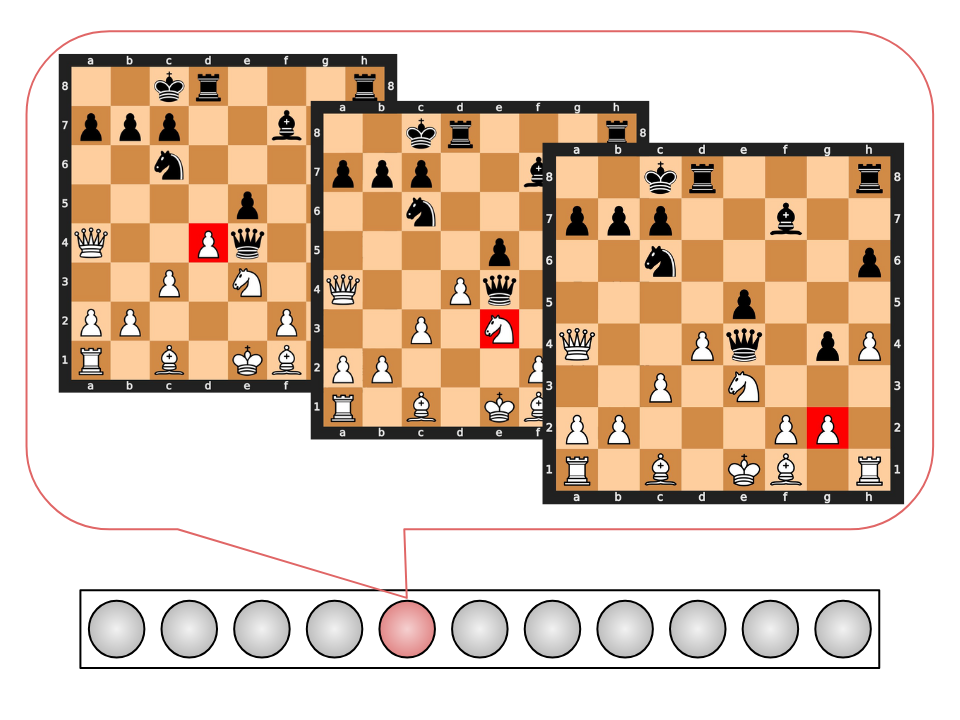
CSAE features analysis.
AI led chess systems to a superhuman level, yet these systems heavily rely on black-box algorithms. This is unsustainable in ensuring transparency to the end-user, particularly when these systems are responsible for sensitive decision-making. Recent interpretability work has shown that the inner representations of Deep Neural Networks (DNNs) were fathomable and contained human-understandable concepts. Yet, these methods are seldom contextualised and are often based on a single hidden state, which makes them unable to interpret multi-step reasoning, e.g. planning. In this respect, we propose contrastive sparse autoencoders (CSAE), a novel framework for studying pairs of game trajectories. Using CSAE, we are able to extract and interpret concepts that are meaningful to the chess-agent plans. We primarily focused on a qualitative analysis of the CSAE features before proposing an automated feature taxonomy. Furthermore, to evaluate the quality of our trained CSAE, we devise sanity checks to wave spurious correlations in our results.
@misc{poupart2024contrastivesparseautoencodersinterpreting,
title={Contrastive Sparse Autoencoders for Interpreting Planning of Chess-Playing Agents},
author={Yoann Poupart},
year={2024},
eprint={2406.04028},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2406.04028},
}